Latest AI News and Innovations
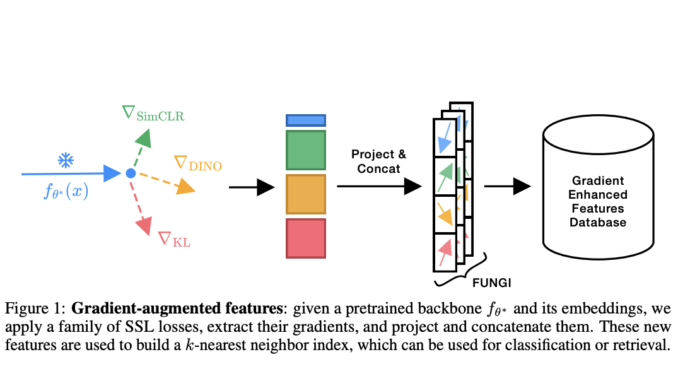
No Train, All Gain: Enhancing Deep Frozen Representations with Self-Supervised Gradients
A central challenge in advancing deep learning-based classification and retrieval tasks is achieving robust representations without the need for extensive retraining or labeled data. Numerous applications depend on extensive, pre-trained models functioning as feature extractors; […]