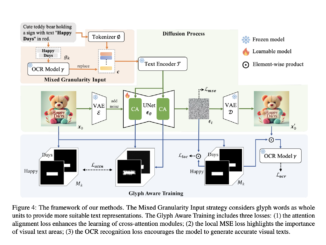
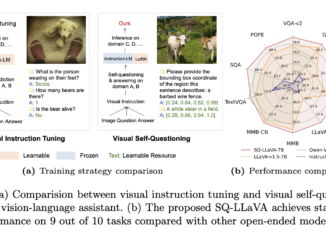
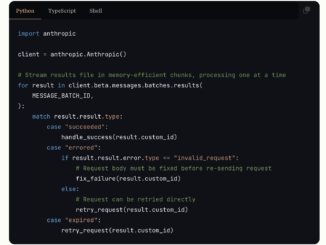
Latest AI News and Innovations
Many organisations unprepared for AI cybersecurity threats
While AI improves the detection of cybersecurity threats, it simultaneously ushers in more advanced challenges. Research from Keeper Security finds that, despite the implementation of AI-related policies, many organisations remain inadequately prepared for AI-powered threats. […]